
MapReduce是一种编程模型,其理论来自Google公司发表的三篇论文(MapReduce,BigTable,GFS)之一,主要应用于海量数据的并行计算。概念Map(映射)和Reduce(归约),是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。

定义
MapReduce 是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce 是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce 是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce 是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言 Lisp 的设计思想,提供了一种简便的并行程序设计方法,用 Map 和 Reduce 两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
由来
MapReduce 最早是由 Google 公司研究提出的一种面向大规模数据处理的并行计算模型和方法。Google 公司设计 MapReduce 的初衷主要是为了解决其搜索引擎中大规模网页数据的并行化处理。Google 公司发明了 MapReduce 之后首先用其重新改写了其搜索引擎中的 Web 文档索引处理系统。但由于 MapReduce 可以普遍应用于很多大规模数据的计算问题,因此自发明 MapReduce 以后,Google 公司内部进一步将其广泛应用于很多大规模数据处理问题。Google 公司内有上万个各种不同的算法问题和程序都使用 MapReduce 进行处理。
2003 年和 2004 年,Google 公司在国际会议上分别发表了两篇关于 Google 分布式文件系统和 MapReduce 的论文,公布了 Google 的 GFS 和 MapReduce 的基本原理和主要设计思想。
Hadoop 的思想来源于 Google 的几篇论文,Google 的那篇 MapReduce 论文里说:Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages。这句话提到了 MapReduce 思想的渊源,大致意思是,MapReduce 的灵感来源于函数式语言(比如 Lisp)中的内置函数 map 和 reduce。函数式语言也算是阳春白雪了,离我们普通开发者总是很远。简单来说,在函数式语言里,map 表示对一个列表(List)中的每个元素做计算,reduce 表示对一个列表中的每个元素做迭代计算。它们具体的计算是通过传入的函数来实现的,map 和 reduce 提供的是计算的框架。不过从这样的解释到现实中的 MapReduce 还太远,仍然需要一个跳跃。再仔细看,reduce 既然能做迭代计算,那就表示列表中的元素是相关的,比如我想对列表中的所有元素做相加求和,那么列表中至少都应该是数值吧。而 map 是对列表中每个元素做单独处理的,这表示列表中可以是杂乱无章的数据。这样看来,就有点联系了。在 MapReduce 里,Map 处理的是原始数据,自然是杂乱无章的,每条数据之间互相没有关系;到了 Reduce 阶段,数据是以 key 后面跟着若干个 value 来组织的,这些 value 有相关性,至少它们都在一个 key 下面,于是就符合函数式语言里 map 和 reduce 的基本思想了。
这样我们就可以把 MapReduce 理解为,把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map 面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出 key 和 value,也就是提取了数据的特征。经过 MapReduce 的 Shuffle 阶段之后,在 Reduce 阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。这就回到了最初,终于知道 MapReduce 为何要这样设计。
2004 年,开源项目 Lucene(搜索索引程序库)和 Nutch(搜索引擎)的创始人 Doug Cutting 发现 MapReduce 正是其所需要的解决大规模 Web 数据处理的重要技术,因而模仿 Google MapReduce,基于 Java 设计开发了一个称为 Hadoop 的开源 MapReduce 并行计算框架和系统。自此,Hadoop 成为 Apache 开源组织下最重要的项目,自其推出后很快得到了全球学术界和工业界的普遍关注,并得到推广和普及应用。
MapReduce 的推出给大数据并行处理带来了巨大的革命性影响,使其已经成为事实上的大数据处理的工业标准。尽管 MapReduce 还有很多局限性,但人们普遍公认,MapReduce 是到最为成功、最广为接受和最易于使用的大数据并行处理技术。MapReduce 的发展普及和带来的巨大影响远远超出了发明者和开源社区当初的意料,以至于马里兰大学教授、2010 年出版的《Data-Intensive Text Processing with MapReduce》一书的作者 Jimmy Lin 在书中提出:MapReduce 改变了我们组织大规模计算的方式,它代表了第一个有别于冯·诺依曼结构的计算模型,是在集群规模而非单个机器上组织大规模计算的新的抽象模型上的第一个重大突破,是到所见到的最为成功的基于大规模计算资源的计算模型。
映射和化简
简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发现所有学生的成绩都被高估了一分,它可以定义一个“减一”的映射函数,用来修正这个错误。)。事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map 操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并(继续看前面的例子,如果有人想知道班级的平均分该怎么做?它可以定义一个化简函数,通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分。)。虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。
分布可靠
MapReduce 通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的返回它所完成的工作和最新的状态。如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同 Google File System 中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。(避免副作用)。
化简操作工作方式与之类似,但是由于化简操作的可并行性相对较差,主节点会尽量把化简操作只分配在一个节点上,或者离需要操作的数据尽可能近的节点上;这个特性可以满足 Google 的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。
用途
在 Google,MapReduce 用在非常广泛的应用程序中,包括“分布 grep,分布排序,web 连接图反转,每台机器的词矢量,web 访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译…”值得注意的是,MapReduce 实现以后,它被用来重新生成 Google 的整个索引,并取代老的 ad hoc 程序去更新索引。
MapReduce 会生成大量的临时文件,为了提高效率,它利用 Google 文件系统来管理和访问这些文件。
在谷歌,超过一万个不同的项目已经采用 MapReduce 来实现,包括大规模的算法图形处理、文字处理、数据挖掘、机器学习、统计机器翻译以及众多其他领域。
其他实现
Nutch 项目开发了一个实验性的 MapReduce 的实现,也即是后来大名鼎鼎的 hadoop
Phoenix 是斯坦福大学开发的基于多核/多处理器、共享内存的 MapReduce 实现。
理解Map和Reduce
MapReduce可以分成Map和Reduce两部分理解。
1.Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
2.Reduce:归约过程,把若干组映射结果进行汇总并输出。
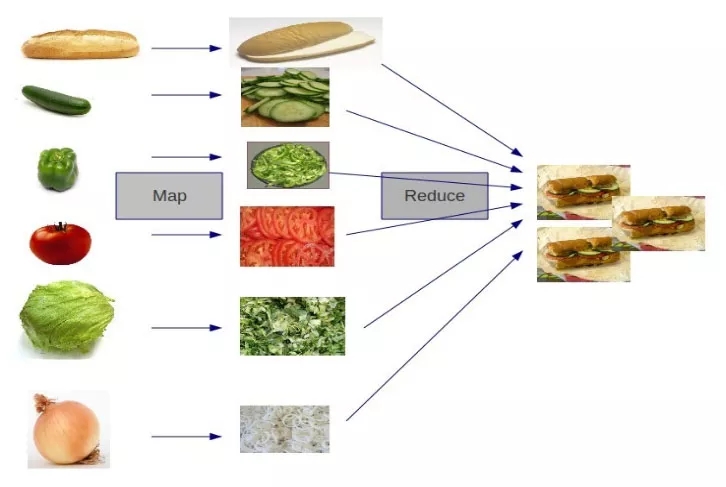
让我们来看一个实际应用的栗子,如何高效地统计出全国所有姓氏的人数?
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:
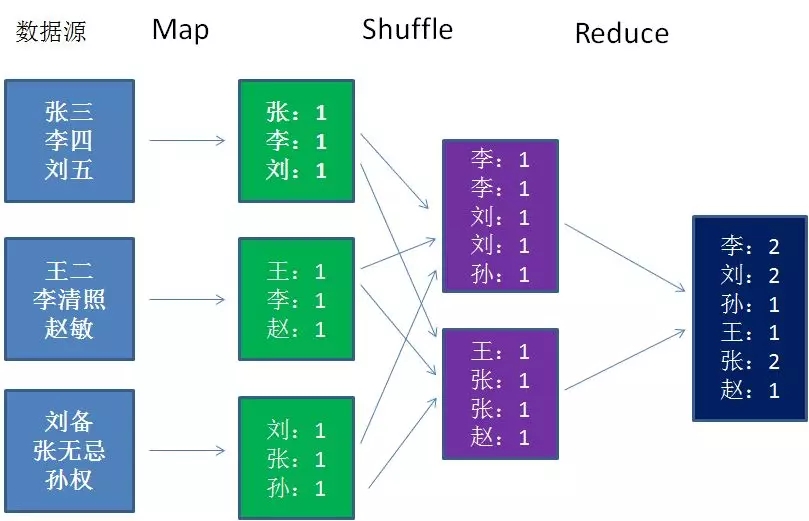
这张图是什么意思呢?我们来分别解释一下步骤:
1.Map:
以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
2.Shuffle
Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
3.Reduce
执行之前分组的结果,并进行汇总和输出。
需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成。










0条评论
点击登录参与评论